即使没有听说过 LAPACK、Intel MKL 和 OpenBLAS 这些高性能计算库,你也一定会对 MATLAB,C++ 中的 Eigen,Python 中的 NumPy 等等强大的数值计算工具有所耳闻。不过,相比于它们的名气而言,它们的来历就鲜为人知了。例如,请你考虑以下两个有趣的问题:
- MATLAB 里的 MAT 是不是 Mathmetics 的简写?
- NumPy、SciPy 中的核心计算部分是不是用 Python 实现的?
如果你的回答都是「是」,那么不妨读一下本文,或多或少会给你增加一些笑料谈资。当然,本文不完全是奇闻轶事的堆积,在段子之余也会通过事例来讨论以下几个比较严肃的问题:
- 科学计算库的发展史带给了我们什么样的启示?
- 我们应该如何看待科学计算领域的「祖传代码」?
- 今天,我们应该选用什么样的科学计算库?
最后,作为我自己的选择和我这几天配置的成果,我会记录一下自己是如何在 macOS(Linux 应该类似)下配置 Intel 数学核心库(Intel MKL)的。
01
1970 年,Argonne 国家实验室。

在近代历史中,数学和计算机的发展总是和战争绑定在一起,战争以其对信息和数据的需要激发了大量科学研究的投入,从而在短时间内推进某一个特殊领域的飞跃式发展。美国的 Argonne 国家实验室,最初是为曼哈顿计划提供核化学支持的研究机构,在战后也继续开展核物理和核化学的研究。
这些研究对数值计算的需要使得研究人员感到有必要开发一种通用的数值计算库,快速完成许多重复的数学过程。与线性代数有关的数学过程是一个非常好的例子:求解线性方程组和求解本征值问题,大多可以归纳为一系列有章可循的操作,从而易于通过算法实现,并封装为库供外部调用。
1960 年代,J. H. Wilkinson 等人总结了这样的一些过程,并收集到《自动化计算手册(第二卷):线性代数》中,其中程序是用 Algol 语言编写的。而在 1970 年代,在阿贡国家实验室的数学与计算科学软件中心成立不久后,一组研发人员继承了上述程序,并补充了一系列有关的库,包括:
- LINPACK:基础的线性代数操作,如矩阵向量乘法;
- EISPACK:矩阵本征系统求解;
- MINPACK:非线性系统与最小二乘系统求解;
这些库都是用 Fortran 编写的,当时 Fortran 的第一个正式版本(Fortran 66)作为第一个科学计算领域的高级语言刚刚发行。不过值得指出的是,运行这些程序的计算机并非我们现在使用的个人计算机(PC),其架构(architecture)也与个人计算机完全不同。例如,考虑到 Fortran 语言是 IBM 为它生产的 704 型计算机设计的语言,让我们来看看这样的计算机通常是什么样子:

显然,如果希望使用这样的计算机,必须向所在的单位(例如,大学具有中央计算主机)提出上机申请并远程操作。1980 年代初期,C. Moler 在新墨西哥大学教授数值线性代数,学生需要执行远程批处理来完成编辑-编译-链接-加载-执行这样的过程才能进行调用上述库进行计算。1另外他们也必须掌握 Fortran。
学生:我就求个本征值,怎么还有这么多乱七八糟的玩意儿???
于是,C. Moler 就用一个更优雅的 Fortran 程序对这些过程进行了封装,取名为「矩阵实验室」,它的界面大概是这样的:

「矩阵实验室」是啥?就是 MATrix LABoratory 呗,我们今天看到的 MATLAB 就是从这里发展起来的。尽管,在 C 语言发展起来之后,MATLAB 的更多模块是用 C 语言实现的,但它的矩阵操作方式仍然和 Fortran 类似。
什么是矩阵操作方式?例如,如果在 Fortran 中希望对矩阵中的元素进行遍历,那么最好这样写:
do j = 1, n
do i = 1, n
A(i, j) = <some expression>
end do
end do
这看上去有点违反直觉,但在 Fortran 程序所操作的内存中,紧邻 A(1,1) 元的元素,确实是 A(2,1) 元而非 A(1,2) 元!因此,如果按行访问,将会不断在内存中跳来跳去,造成资源浪费。在今天的 MATLAB 中,矩阵的操作依然是列优先的。当然,作为今天的 MATLAB,它支持的常微分方程数值解、快速 Fourier 变换等内容,就是很久以后的事情了。
02
1990 年,Netlib。
刚才提到,1970 年代的用于科学计算的计算机使用的处理器和个人电脑所使用的是不同的。前者,严格来讲算是一种「向量处理器」,其中 CPU 处理的是能够同时操作一个向量(即一维序列)的指令集2,显然这样的处理器是很适用于科学计算的。
然而从 1990 年代开始,随着个人电脑进入市场和 Intel 处理器的盛行,大家更愿意在自己的电脑上编写程序进行计算。个人电脑是通用型的,这意味着它不会针对科学计算设计特殊的指令集,这对科学计算库的编写提出了新的要求。
一个名为 Netlib 的组织不仅继承了 EISPACK 这些已有的包,还针对现有架构进行了进一步的封装和改善。LAPACK(线性代数包)就是一个适用于更加现代的架构的后继者。尽管这些处理器无法进行向量指令集的操作,仍然能够通过充分利用缓存(提高命中率)来提升效率,这使得相比于直接在这些电脑上运行 LINPACK 等程序效率高得多。
这些更加低级的(与硬件有关的优化)实际上是通过 BLAS(基本线性代数子程序)来完成的,它定义了诸如向量加法、标量与向量的乘法和点乘等等线性代数的基本过程,并根据特定的处理器进行优化。3这里的黑科技有时候看上去会非常难以理解,例如:
我们一般认为矩阵乘法是 时间复杂度的,因为 对每个元素都要循环 次,而元素的数量是 的,总体结果当然是 的。但在真正的高性能计算中,复杂度会降到 甚至更低。所以自己还是没事不要瞎造轮子。
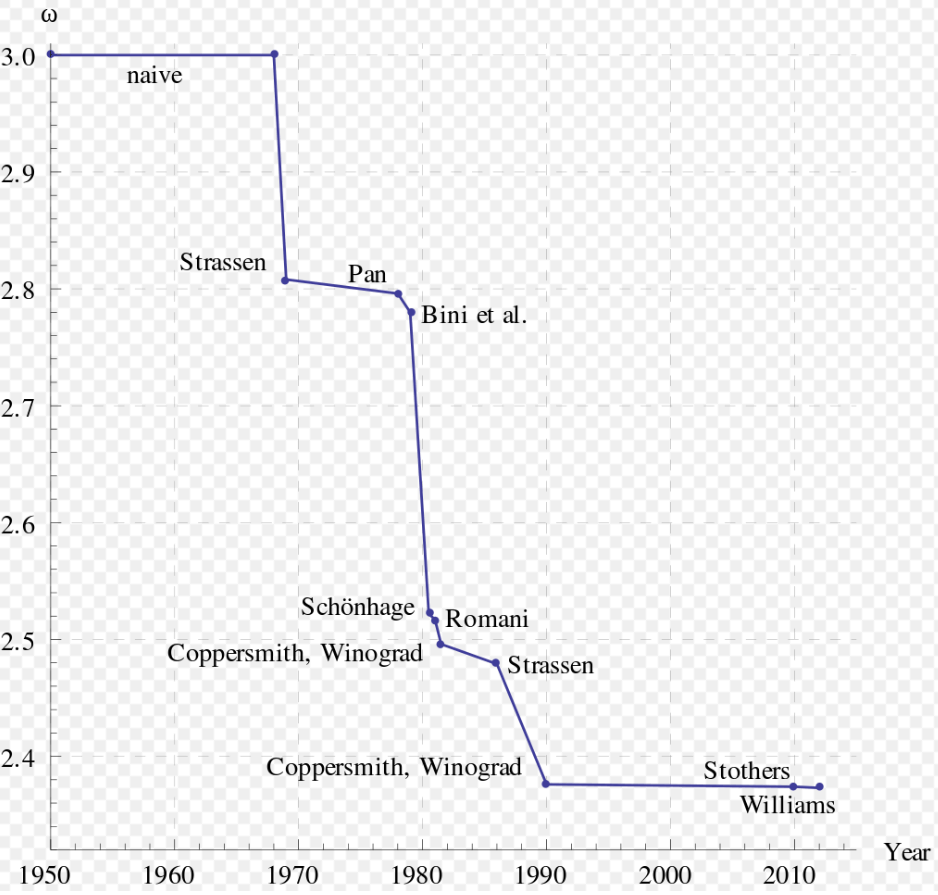
LAPACK 尽管是用古老的 Fortran 77 语言写的,但确实相当完善并久经检验,以至于它已经几乎成为了各种更加高级的库默认的底层实现。当我上周查找关于 LAPACK 的资料的时候,我惊奇的发现 LAPACK 竟然是 macOS 系统自带框架的一部分。4如果希望在 macOS 系统中使用 LAPACK,只需要在编译时加上 -framework accelerate 就可以了。例如
gfortran xx.f90 -o xx -framework accelerate
于是我又多了一个吹 macOS 的理由。
不过虽然是这么说,但如果你真的打算直接调用 LAPACK,那你可能还需要再想一想。一个典型的 LAPACK 函数,例如实对称矩阵的本征值问题,大概是这个样子的:
! Fortran 接口
call ssyev(jobz, uplo, n, a, lda, w, work, lwork, info)
或者
// C 接口
lapack_int LAPACKE_<?>syev( int matrix_layout, char jobz, char uplo, lapack_int n, <datatype>* a, lapack_int lda, <datatype>* w );
除了必要的 A 是矩阵输入,w 是本征值输出之外,其他对象对你要解决的问题来说,啥用没有,仅仅是指定了 LAPACK 工作中的一些细节。这是因为,Fortran 77 并不支持数组的动态大小,所以不仅需要额外提供给 LAPACK 一个矩阵维数,还要提供一些向量作为「工作空间」,以防存储空间不够用。声明这些无用的变量并初始化它们显然会对你程序的明晰程度产生一定的影响~~,并强烈损害了我这样的强迫症的使用体验~~。
好在 Fortran 95 的泛型编程和显式接口很大程度上解决了这个问题。由于这不是一篇介绍现代 Fortran 的文章,具体实现的方法就不作展开了,但当使用 Fortran 95 调用的时候,可以简单地写成
! Fortran 95 接口
call syev(a, w, job)
注意这里的 ssyev 前面指定单精度数的那个 s 也可以省略不写。
一个字,爽!
很多 C/C++ 的数学库也调用了 LAPACK,并做了针对 C 语言的进一步优化。我没有使用过 C 和 C++,但据工位邻桌的老哥的使用体验,Eigen 是一个不错的选择。
03
2000 年,Intel。
前面看到,正是个人电脑处理器的更新换代促使了数学库的更新换代。那么,作为以压倒性优势占领处理器市场的大佬,Intel,咋能不搞点事情呢??
首先要说明的一点是,MacBook 系列使用的也是 Intel 处理器~~(只不过只有 Apple 公司不愿在自己的电脑上给 Intel 做广告,所以一般大家都不知道)。以下讨论中凡涉及到硬件的,默认是在 2018 MacBook Pro 所搭载的 2.3GHz 八核 Intel Core i9 处理器上进行的测试,以拒绝抬杠~~。
2003 年,Intel 在它开发的编译器(icc、ifort 等)的基础上搞了一个东西叫 Intel MKL(数学核心库),它不仅包括了前面说的线性代数的功能,还包括 Fourier 变换,微分方程,非线性方程和统计等功能。当然,线性代数底层也是 BLAS 和 LAPACK 实现的,不过 Intel 显然做了更好的优化。有意思的是,Intel MKL 手册几乎每一部分的开头都有这样一段话:
Intel MKL is optimized for the latest Intel processors, including processors with multiple cores. Intel’s compilers may or may not optimize to the same degree for non-Intel microprocessors for optimizations that are not unique to Intel microprocessors.
(我怀疑你故意减慢了在其他处理器上的运行速度,但我没有证据。)
简单来说,Intel 搞了什么指令集,Intel 自己最清楚,所以可以在编译的时候根据指令集进行终极优化。让我们来做一个简单的测试,对比 「gfortran 编译器调用 Accelerate 框架」与 「ifort 编译器调用 Accelerate 框架」在计算 1000 × 1000 矩阵乘法时的表现。先放上源代码:
program main
implicit none
integer :: i, j, k
integer, parameter :: n = 1000
real(8) :: a(n,n) = 1, b(n,n) = 1, c(n, n) = 0
real :: t1, t2
call cpu_time(t1)
do j = 1, n
do i = 1, n
do k = 1, n
c(i, j) = c(i, j) + a(i, k) * b(k, j)
end do
end do
end do
call cpu_time(t2)
print *, '造轮子:', t2 - t1
call cpu_time(t1)
c = matmul(a, b)
call cpu_time(t2)
print *, '自带矩阵乘法:', t2 - t1
call cpu_time(t1)
call sgemm('n', 'n', n, n, n, 1d0, a, n, b, n, 0d0, c, n)
call cpu_time(t2)
print *, 'BLAS:', t2 - t1
end program
输出结果是:
$ ifort speed.f90 -O3 -o speed -framework accelerate && ./speed
造轮子: 0.1375380
自带矩阵乘法: 0.1311140
BLAS: 3.3599138E-04
$ gfortran speed.f90 -O3 -o speed -framework accelerate && ./speed
造轮子: 1.04389393
自带矩阵乘法: 9.80659723E-02
BLAS: 3.60965729E-04
可以看到,按造轮子写循环的写法,ifort 的优化功力很强,优化到了自带矩阵乘法的水平,这可能是因为 ifort 能够更好地进行底层向量化处理。调 BLAS 库又比自带矩阵乘法快了两个数量级,不过后面这两个级别就与用什么编译无关了。
虽然我们并不会真的去造轮子,但我们并不是所有的语句都可以调库完成,总会有一些「冗余」的写法等着编译器来「擦屁股」,所以还是有一定用处的。
不过当调用 MKL 库中的 BLAS 时,反而慢了一些,我很意外,目前还不清楚是为什么。可能还是硬件生产商干不过操作系统生产商?
最后放一张目前提到过的几乎所有库的对比:
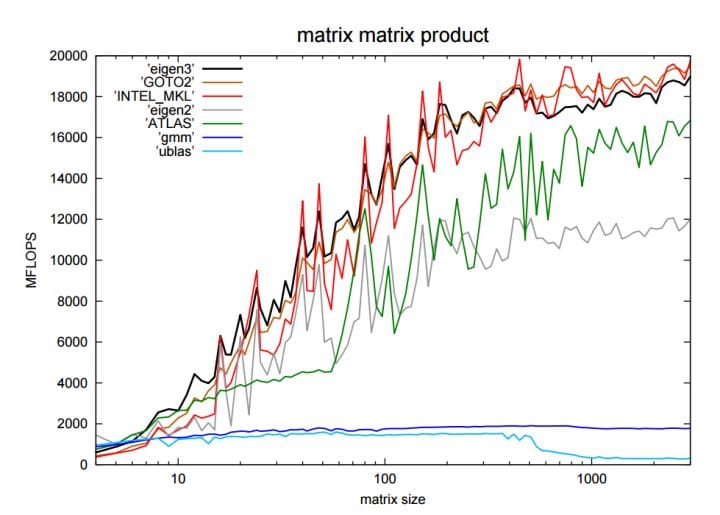
MKL 和 Eigen 3,作为 BLAS 的两种不同封装,不相上下,共领风骚。
总之,LAPACK 是对 BLAS 的调用,绝大多数与线性代数有关的库,包括前面没有提到的 ATLAS(为硬件优化的 BLAS)和 OpenBLAS(在运行时自动调整的 BLAS),都同时调用了 BLAS 和 LAPACK,使得它们事实上成为了线性代数的标准「API」。
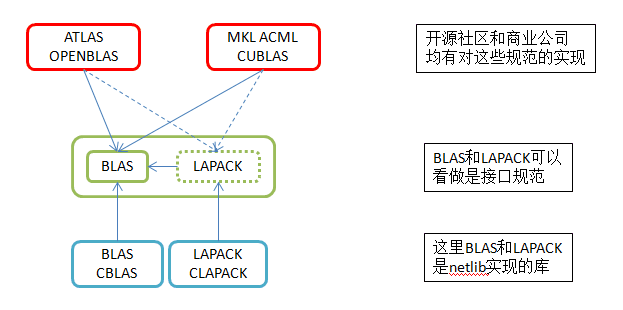
在结束本段之前,似乎还可以讨论一下这些库在并行计算上做的文章。的确,Intel MKL 加上 Intel Fortran 编译器理论上可以自动把八核跑满,不过我一般不这么干(爱惜电脑,笑),而在课题组的集群上用 mpirun 调用几十个核搞事情又是另一个问题了,以后打算单独用一篇文章讨论。
04
2010 年,大楚兴,Python 王。
在科学计算领域,Fortran 无疑是常青树,C++ 也是一大利器,但目前来看,越来越多的人愿意用 Python 这样的更加易读易写的脚本语言进行开发。众所周知,Python 的解释过程相比于 Fortran、C++ 等先编译再运行的过程慢了很多(即使考虑到可以用 Cython 等方法增强解释性能),在运算密集的场合,需要有一些邪招来顶事。
NumPy 就很快,而且是巨快(相比于 Python 的解释过程而言)。以至于会有人问:
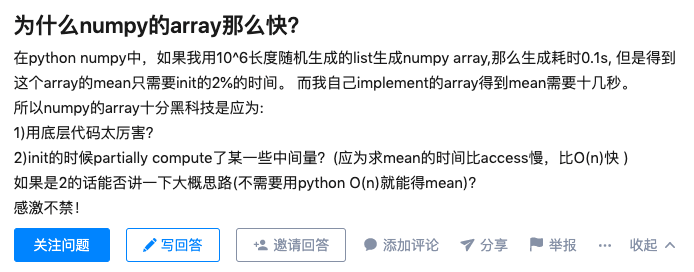
首先,NumPy 的 ndarray 对象是用 C 语言写的。其次,这也并不代表它与 Fortran 没有关系,因为用 C 语言调用的库是根据当前系统存在的库动态调用,很有可能调用到的还是 LAPACK、Eigen、Intel MKL 这一套(万物归 BLAS??)。NumPy 进而又构成了 SciPy 和 Pandas 等等生态圈的核心组分。
但如果说 Python 和它的数值计算库代表了这个领域的最新成果,也不对。2010 年之后,有一种听上去很 nb 的语言渐渐进入了人们的视野,创作者们宣称:
我们想要一种具有自由许可的开源语言。希望拥有 C 的速度和 Ruby 的灵活。我们想要一种同像性语言,有像 Lisp 这样真正的宏,而又有 MATLAB 般浅显熟悉的数学符号;我们想要一门像 Python 一样可用于通用编程、像 R 般在统计分析上得心应手、像 Perl 般自然地处理字符串、像 MATLAB 般具有强大的线性代数运算能力、像 shell 般擅长将程序粘合在一起的语言。它简单易学,却又让严苛的黑客为之倾心;还有,我们希望它是交互式的,同时具备可编译性。
令人惊讶的是,上面这段梦话一般的宣言,可以说某种意义上确实在这种语言——Julia——中实现了。简单来说,相对于 Python,Julia 减少了一些动态性,使得它经过优化后能达到 C++ 和 Fortran 相当的运算速度,同时保留着较强的可读性。另外,Julia 是专为科学计算设计的,这意味着它是与 Fortran 对标的后继者。
不过,Julia 语言的 1.0 版本 2018 年才刚刚发布。部分库的生态不佳,各种用户学习资料也不如 Python 完善,并且它的专用性也阻碍了更多资源的投入。总之,一个编程语言的兴衰,要在 10 年的尺度上才能看出来,现在来讲,也许你可以和我一样持观望态度。Julia 就像 Tesla,它是以改变未来这一大胆目标而建立。它可能会做到,但它也可能只是一个脚注。
05
2020 年,又是谁家天下?
现在,我们可以回头看看在文章开头提出的几个问题。
Perl 语言的发明者曾经表示,程序员最大的三个优点就是懒惰、烦躁和傲慢。在某种意义上,用程序进行科学计算的科学家比程序员更好地拥有了这三个品质:他们并不是真正希望学习编写程序,所以在这一方面他们更懒惰、更烦躁和更傲慢。无论是 C. Moler 的 MATLAB,Netlib 的 Fortran 95 接口还是 NumPy 的 ndarray,都在致力于将这群「伪」程序员的注意力转移到发现新的科学而非转移到程序的具体计算细节上。在大多数情况下,关注计算细节能让我们获得更好的性能,但性能,从某种历史的角度看,确实是我们这个摩尔定律尚未失效的年代相对来讲不值钱的东西。
于是我们怀着崇敬的心情,将历史遗留下来的代码进行一二三四五层封装,隔着这样的层层面纱用 syev() 或者 np.linalg() 调用它们(它们久经考验,以至于我们确实不需要通过检查它们的源码来调试)。我们是这个时代中「敬而远之」这个词的最好践行者,把历史当成基石而非重担才能让我们看得更高,走得更远。
而这些库的所有者,从国家实验室,到一般的科研机构,再到商业公司的演变,也从侧面印证了这些年来「科学计算」疆域的扩展。当我们选择一个库为我们服务时,除了优雅的接口和高超的效率之外,详细的文档、稳定持续的更新和用户社群也是需要考虑的因素之一,目前看来,商业公司似乎能够更加胜任这一工作。(作为类比,请考虑 macOS 本质作为「封闭落后的类 Unix 系统」和 Linux 本质作为「开放先进的类 Unix 系统」哪一个更加有吸引力呢?)
尽管没有必须亲自操作祖传代码的压力,在 2019 年这个时间节点看来,我还是选择了 Fortran,选择了 Intel MKL 和绑定在其上的 Intel Fortran 编译器。总有一天 Fortran 会像 Algol 一样被扔进历史的垃圾桶,但来扔的后继者不会是 C++,也不太像是 Python 和 Julia 这样的新秀。
让我们在更大的时间尺度上拭目以待吧。
在 macOS 上使用 Intel MKL
以下是在 macOS 系统上的配置过程。除此之外,如果你是在 Linux 系统(如服务器)上配置,那么过程应该大同小异。
下载
值得称赞的是,MKL 是 Intel 公司为数不多开源免费的良心之作(近几年来才如此)。不过考虑到它需要用 Intel Fortran 编译器才能调用,我们可以索性下载一个 Intel Parallel Studio XE,其中会集成一个 MKL。下面我们以 Parallel Studio XE 为例说明它的使用方法。
首先,Parallel Studio 对学生是免费的,访问登记页面选择 Fortran 或者 C++ 版本的,点进去登记个人信息即可下载。
下载得到的文件名应该类似于 m_fcompxe_2019.4.047.dmg,点击安装并输入序列号即可。
配置编译器
在浏览器中访问本地的安装指南,路径应该类似于 /opt/intel/documentation_2019/en/ps2019/getstart_comp.htm,按照上面的指示,将 ifort 添加到环境变量中:
source <install_dir>/bin/compilervars.sh intel64
其中 <install_dir> 默认是 /opt/intel/compilers_and_libraries_2020.0.166/mac/。然后进行编译器测试:
ifort Hello.f90
如果配置成功,应该生成 a.out 文件。
配置 MKL
现在打开 MKL 的安装指南(建议下载 PDF 阅读,网页访问非常慢),按照上面的指示,将 MKL 添加到环境变量中:
source <install_dir>/mkl/bin/mklvars.sh intel64 mod
其中 intel64 是指定架构,mod 是将 Fortran 的模块进行预编译。(2019 年 12 月 21 日补充:在 macOS 上,你可能需要将这句命令添加到你的 .bashrc 或 .zshrc 中,这样每次打开终端会话时都会自动配置环境变量。)
链接
帮助文件提供了很多种不同的链接方式,我没有完全搞懂,但我选了一种比较简单的链接命令:
ifort Hello.f90 -o Hello -mkl -lmkl_lapack95_lp64
你可以复制这个命令,然后使用这个测试程序进行测试。当然,每次编译都输入这么长的命令是会死人的。如果你也和我一样使用 Visual Studio Code 作为编辑器的话,可以使用这个任务文件来将编译运行过程自动化。
{
"version": "2.0.0",
"tasks": [
{
"label": "编译 Fortran 源代码",
"type": "shell",
"command": "ifort ${fileBasename} -o ${fileBasenameNoExtension} -mkl -lmkl_lapack95_lp64",
"options": {
"cwd": "${relativeFileDirname}",
},
"group": {
"kind": "build",
"isDefault": true
},
"presentation": {
"focus": true
}
}
]
}
注意,如果调用 LAPACK,那么程序中直接 call 相应的子例程即可;如果通过 LAPACK 95 接口间接调用 LAPACK,那么还需要导入接口模块,例如上面用来测试的 Hello.f90 源码是:
include 'lapack.f90'
program main
use lapack95
use f95_precision
implicit none
real*8 :: a(2,2) = 0
print *, 'Hello Intel MKL!'
a(1,1) = 1
call getrf(a)
print *, 'The result is:', a
end program
数学参考
MKL 还提供了一份帮助文件详细说明了每个过程的输入输出以及使用方法~~,这一点真是比原生的 LAPACK 高到不知道哪里去了。~~强烈建议下载 PDF 版本。
- https://ww2.mathworks.cn/company/newsletters/articles/a-brief-history-of-matlab.html[↩](about:blank#fnref1)
- https://en.wikipedia.org/wiki/Vector_processor[↩](about:blank#fnref2)
- https://en.wikipedia.org/wiki/Basic_Linear_Algebra_Subprograms[↩](about:blank#fnref3)
- https://developer.apple.com/documentation/accelerate[↩](about:blank#fnref4)