在引出今天的主题之前,我有必要先解释一下本文的题目。近几年来,通用型智能机器人已经可以以一种「可学习」的方式胜任越来越多的工作。然而,如果仅就「收麦子」这一件工作而言,智能机器人的效率必然远远不及大型联合收割机,这是由后者的高度专门化的硬件结构所决定的。
在高性能计算领域,如果说通用的计算集群是上述例子中的「智能机器人」,那么具体的计算任务就是各种不同的「工作」。众所周知,计算化学中的分子动力学模拟对性能有着很高的要求,那么一个很自然的问题就是:我们能不能设计分子动力学专用的「大型联合收割机」呢?
这样做的其中一个缺陷是显而易见的:通用计算机的性能发展是被世界上所有计算需求驱动的,它受益于 Moore 定律(单位计算性能的成本每 18 个月降低一半)带来的指数增长;而个人或团体很难投入如此大的时间和金钱资源用于推动(只有自己人感兴趣的)专用计算机的发展。如果 Moore 定律不失效,从长久来看,通用计算机的反超一定会发生。
那么,计算化学领域的「大型联合收割机」是否一定没有前途呢?为了回答这个问题,我们首先来回顾科学史上的另一段故事。
2
17 世纪中叶,生物学的研究尚未进入现代微生物学范畴,而原因当然是表征手段落后。彼时光学显微镜的分辨率大约在 量级,距离实用的微生物观测约差两个数量级——无怪乎微生物研究尚未引起重视。我们今天所熟知的微生物学之父——列文虎克(Antonie van Leeuwenhoek)的突出贡献就在于,通过自己对于棱镜的技术研究,将分辨率提高了 500 倍,从而开创了崭新的研究领域。

列文虎克和他的光学显微镜
在我们一般人的印象中,在性能上进行「量」的积累是平凡的工作,远远不及揭示「质」的新发现重要;然而,如上述实例中量的积累导致质的突破的情况在科学史上屡见不鲜,在某一个特殊的时间节点,一些小的改进引发了巨大的回报。
再说回分子动力学(Molecular Dynamics, MD)。MD 的终极目标是模拟大尺度、长时间的复杂系统运动,从而提供关于系统的丰富信息;其中特别值得注意的一类系统即是生物大分子的相互作用。蛋白质折叠、基因组的活动、药物与靶标的相互作用……这些重要现象大约发生在微秒()量级。然而,MD 模拟的一个典型时间步长是飞秒(),在现代的高性能计算集群上运行一天,大约可以演化这类系统几个纳秒。
MD 今天的困境,就如同 17 世纪微生物学研究的困境:要想在几周之内获得有价值的结果,我们的计算性能必须提高 2 至 3 个数量级,在 Moore 定律不失效的前提下这需要 20 年左右来达成。然而,今天我们也许也可以像列文虎克那样,通过专门化的技术「抄近道」,提前达到这一临界水平。具体来讲,如果计算机的专门化能提高 1000 倍的性能,将能够领先通用计算机相当长的一段时间。
3
在所有试图将 MD 计算专门化的尝试中,D. E. Shaw 研究组得到了最有影响力的几个结果之一。Shaw 的传奇经历我最初是在关于计算化学的一个知乎回答中看到的,在此不作展开;只需要知道他作为一个计算机教授,用高频交易挣来的钱开了一家计算化学研究所就可以了。Shaw 组的工程师们把他们造的专用计算机命名为 Anton,即取列文虎克的名字以向其致敬。
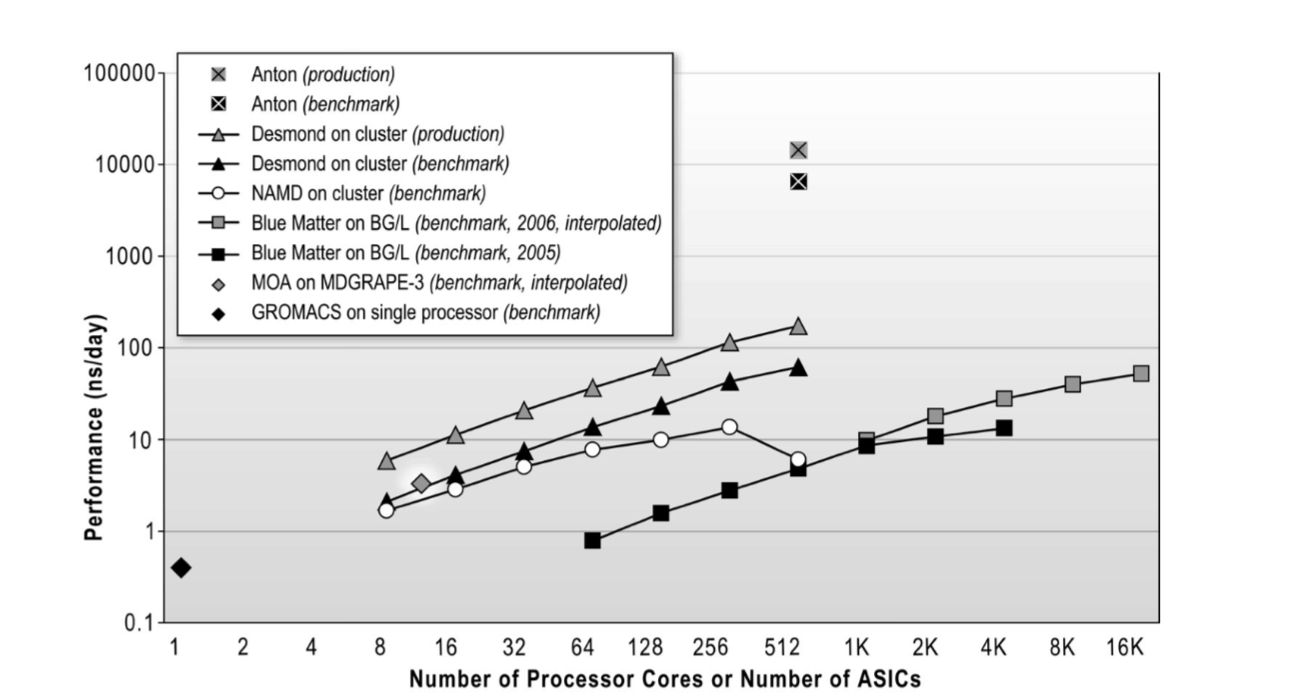
Anton 一代比最快的超级计算机快了 100 倍,二代又比一代快了 10 倍
从 2004 到 2008 年,一大批工程师、化学家和生物学家汇聚在 Shaw 的门下,做出了 Anton 一代;2014 年又发布了 Anton 二代。Anton 用碾压全球的计算能力在各种顶级期刊上灌水的事情略过不表,但它确实将 MD 模拟推向了实用。
当然,在学术界,Shaw 并没有那么好的名声——Shaw 组的工作,其他科研机构的人完全无法重复,对发现新的化学和生物研究动向也没有多少参考价值。尽管如此,即使我们不关心 Shaw 组的研究,我们还是可以通过解读 Anton 的架构来增长我们自己的智慧,理解许多计算难题的核心所在。
4
以上是科普向的内容,下面则是对其原理的解读。
众所周知,在经典 MD 中我们将整个体系的能量划分为这几部分:
总能量中既有化学键的贡献()也有非化学键的贡献()。化学键的贡献又可以分为三类:
- 由两个相连原子的相对位置决定的长度对能量的影响();
- 由三个相连原子的相对位置决定的键角对能量的影响();
- 由四个相连原子的相对位置决定的二面角对能量的影响();
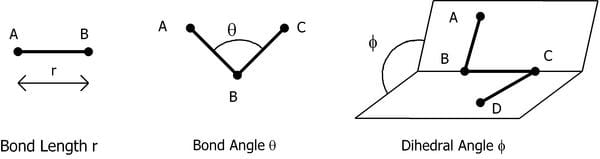
三种化学键的贡献
而非化学键的贡献又可以分为静电(,永久电荷、偶极和多极等)相互作用和范德华(,含诱导偶极和多极)相互作用。
如此一来,我们就把能量表达为了所有原子坐标的函数。系统的运动方程因此可以写为:
在 MD 中,绝大多数的计算都归结为这个力的计算。然而,不同种类能量的梯度对应的力有不同的特性:化学键的贡献和范德华力都是短程力,一个原子只与周围几个原子作用,计算量与系统大小呈线性关系;而剩下的静电力却是长程力,相互作用个数与系统大小呈平方关系。
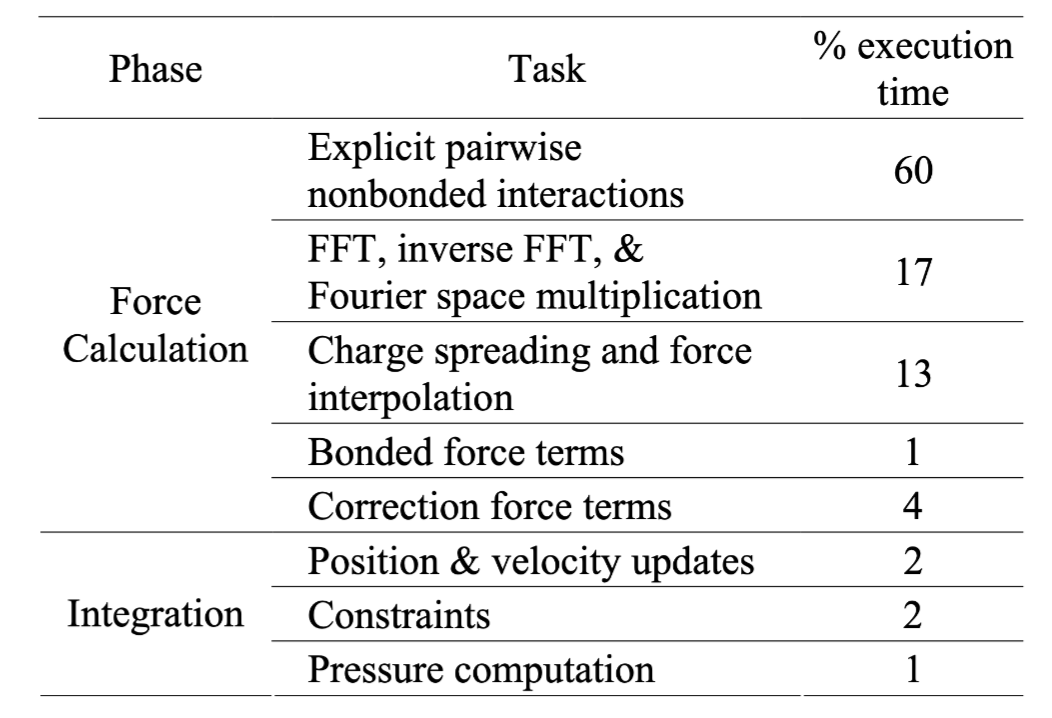
用 GROMACS 进行 MD 模拟的时间分析
因此,加速 MD 的关键就在于加速静电相互作用的计算。尽管存在 k-GSE 等方法将复杂度由 降为 ,这仍是耗时最多的一部分。
下面我们简要从通信和计算两个角度介绍 Anton 中最重要的性能提升技术。
5
首先是通信。Anton 具有 512 个计算节点,它们在空间上的排布使得相当于将被模拟的系统分为 8 × 8 × 8 的盒子,每个盒子只负责 1/512 的原子,每个节点和盒子一一对应,并且只需要和邻近的 6 个节点通信。
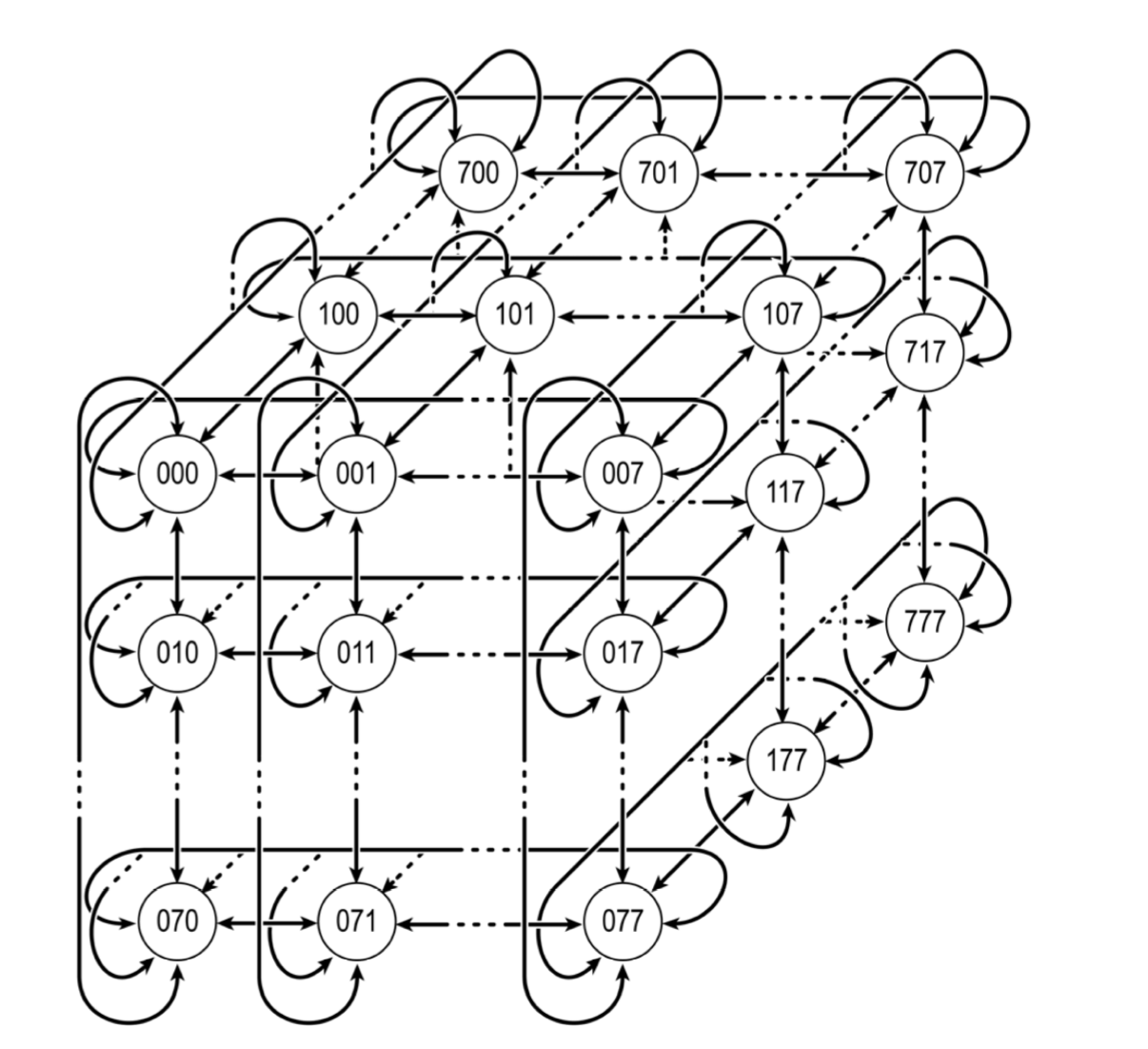
Anton 的整体架构
这听起来和当前常用的 LAMMPS 等大规模并行 MD 库很类似,但实际上有本质的区别。这些库中通信基于类 MPI 的「共享内存式并行」,把需要共享的数据放到公共空间各自读取;而这里每个节点之间都有点对点的专用信道,不存在访问资源的冲突问题。
对于 MD 而言,主要的通信内容是处在盒子边界的原子的位置,只有进行准确的通信我们才能够准确计算这些原子与其他原子之间的作用力。由于低时延(约 50 ns)、高带宽的一对一信道的建设,大大减少了计算节点间通信需要的时间。
于是剩下的问题就是:每个节点如何高效进行一个时间步长的计算?
6
如果你还没有忘记大一学过的计算概论的基础知识的话,你应该了解计算机的工作是以「时钟周期」为单位的。在一个时钟周期内,CPU 进行一个字(word)大小数据的处理,然后与缓存等高速设备交换信息。目前,常见的个人电脑的频率大约是 3 GHz。
在 Anton 中,时钟周期被巧妙地赋予了一层物理含义:一个时钟周期就对应着被模拟系统的一个时间步长。在一个时钟周期内,每个节点内集成电路的各个组件相互同步配合,完成了力的计算和运动方程的积分。具体来说,除去节点间通信外,每个节点由三部分组成:
- HTIS(高通量相互作用子系统):对计算最密集的静电相互作用和范德华相互作用进行计算,输入每对原子的位置信息,用 32 个模块并行计算受力;
- Flex(可变功能子系统):完成剩余全部工作,包括运动方程积分、FFT、化学键贡献的相互作用等;
- 节点内通信网络:为以上两个计算子系统提供或输出数据。
注:由于 MD 的低内存消耗(只需要处理 O(n) 的位置、动量和力)特性,我们实际上只需要以上几个计算单元各自的缓存来存储数据就可以了,而完全不需要内存。换句话说,这是一台只有 CPU 的计算机……
在每个时钟周期中,HTIS 和 Flex 共同算力,然后 Flex 完成积分,通信网络获取更新的位置进行同步,就完成了一个时间步长。
Anton 二代还采用了更激进的「细粒化」方法进一步加强了同步效果,即对每个原子的数据进行精细化处理,使得上一个步骤未结束时下一个步骤即能开始。例如,位置同步没结束时,已经有一部分原子上的力可以计算了,那么就这样做;力计算没结束时,已经有一部分原子可以积分了,那么就这样做;等等。
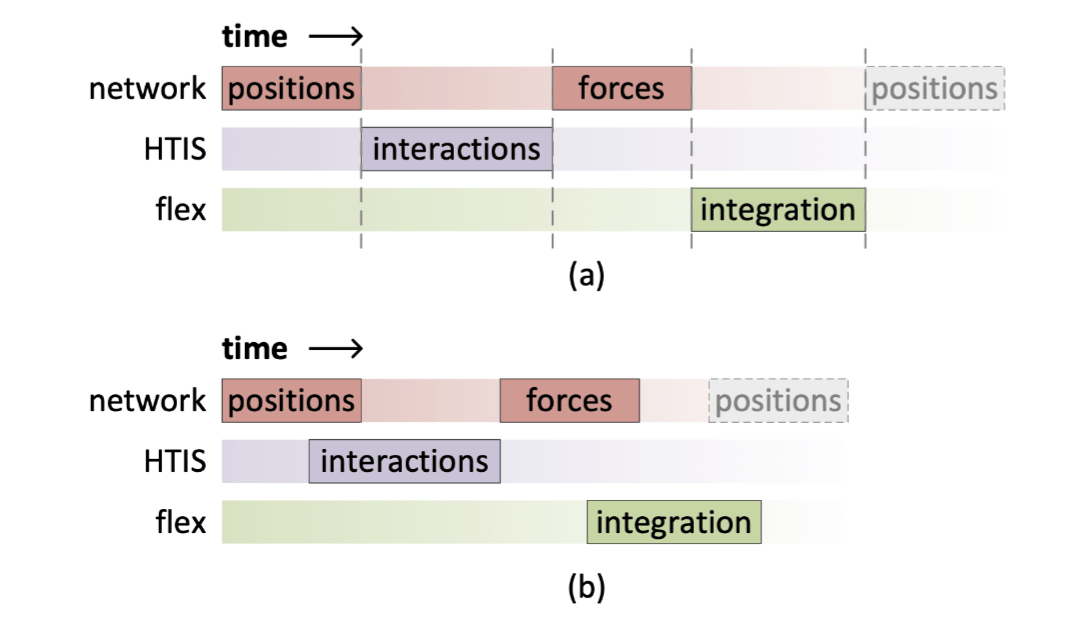
Anton 的时钟频率约为 500 MHz(二代 1.6 GHz),听上去不高,但由于通用计算机中没有上述的配合条件,几十个甚至上百个时钟周期才能完成一个时间步长,因此 Anton 的效率要高得多。
7
如果给你一个机会,让你了解你所处的领域 20 年后在做哪些事情,你会怎么想?希望你可以在评论区与我们分享。
Anton 的计算能力能做到这一点,在某种意义上它是新时代的列文虎克,在未来的某一天也许就会带来许多新的机遇。